School is out for Christmas (I had my last exam last Friday), so now I have time do fun things, like coding (surprise).
I think algorithmic programming and databases and SQL queries are cool things, so why not combine them? Yesterday I got an idea of implementing some well-known algorithm in SQL, and I figured out that Dijkstra's Shortest Path algorithm should be fun to implement.
Dijkstra's shortest path algorithm finds, well, the shortest path from one vertex to the other vertexes in a weighted graph. The edges have lengths (or costs or whatever), and the shortest path from one vertex to another is the path where the sum of these lengths are as small as possible. Take a look at the illustration below, showing a graph with some Norwegian cities. The shortest path from Trondheim to Fredrikstad has been highlighted (for those of you that know Norway, not very realistic, but let's pretend it is just for the fun of it).
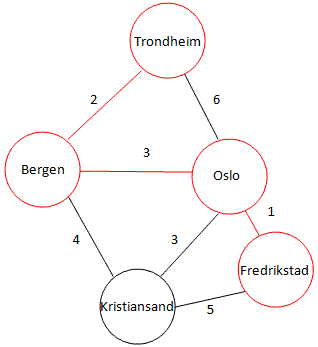
The algorithm works like a breadth first search that takes the edge weights into account, starting at one vertex and traversing through the graph.
So, how do we implement this in Transact-SQL (MS SQL Server's SQL dialect)? Well, first we need some way to represent the graph. I've created two tables:
City
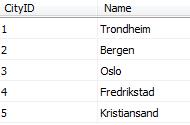 |
Road
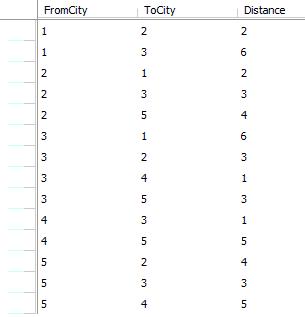 |
The City table is pretty straightforward. The Road table contains one row for every road from one city to another, and the length of that road. Notice that we have two rows for every two cities we have a road between them, one each way. But, now to the real stuff: The implementation of the algorithm:
CREATE PROCEDURE [dbo].[Dijkstra]
@StartCity Int
AS
BEGIN
-- Automatically rollback the transaction if something goes wrong.
SET XACT_ABORT ON
BEGIN TRAN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON;
-- Create a temporary table for storing the estimates as the algorithm runs
CREATE TABLE #CityList
(
CityId Int NOT NULL, -- The City Id
Estimate Int NOT NULL, -- What is the distance to this city, so far?
Predecessor Int NULL, -- The city we came from to get to this city with this distance.
Done bit NOT NULL -- Are we done with this city yet (is the estimate the final distance)?
)
-- Fill the temporary table with initial data
INSERT INTO #CityList (CityId, Estimate, Predecessor, Done)
SELECT CityId, 2147483647, NULL, 0 FROM City
-- Set the estimate for the city we start in to be 0.
UPDATE #CityList SET Estimate = 0 WHERE CityID = @StartCity
IF @@rowcount <> 1
BEGIN
RAISERROR ('Couldn''t set start city', 11, 1)
ROLLBACK TRAN
RETURN
END
DECLARE @FromCity Int, @CurrentEstimate Int
-- Run the algorithm until we decide that we are finished
WHILE 1=1
BEGIN
-- Reset the variable, so we can detect getting no records in the next step.
SELECT @FromCity = NULL
-- Select the CityID and current estimate for a city not done, with the lowest estimate.
SELECT TOP 1 @FromCity = CityId, @CurrentEstimate = Estimate
FROM #CityList WHERE Done = 0 AND Estimate < 2147483647
ORDER BY Estimate
-- Stop if we have no more unvisited, reachable cities.
IF @FromCity IS NULL BREAK
-- We are now done with this city.
UPDATE #CityList SET Done = 1 WHERE CityId = @FromCity
-- Update the estimates to all neighbour cities of this one (all the cities
-- there are roads to from this city). Only update the estimate if the new
-- proposal (to go via the current city) is better (lower).
UPDATE #CityList SET #CityList.Estimate = @CurrentEstimate + Road.Distance,
#CityList.Predecessor = @FromCity
FROM #CityList INNER JOIN Road ON #CityList.CityID = Road.ToCity
WHERE Road.FromCity = @FromCity AND (@CurrentEstimate + Road.Distance) < #CityList.Estimate
END
-- Select the results.
SELECT City1.Name AS ToCity, Estimate AS Distance, city2.Name AS Predecessor FROM #CityList
INNER JOIN City city1 ON #CityList.CityId = City1.CityID
LEFT OUTER JOIN City city2 ON #CityList.Predecessor = city2.CityID
-- Drop the temp table.
DROP TABLE #CityList
COMMIT TRAN
END
If we run it with Trondheim as start city (@StartCity = 1), we get this result table:
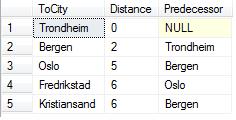
This says that from Trondheim, we have a distance 0 to Trondheim, 2 to Bergen and so on, and 6 to Fredrikstad. The Predecessor column says what city we came from when we went to each city. We can see that to get to Fredrikstad, we came from Oslo, and to get to Oslo, we came from Bergen. To get to Bergen, we came from Trondheim. Therefore, to get to Fredrikstad, we took the path Trondheim, Bergen, Oslo, Fredrikstad.
I have included the SQL script to create the database:
Dijkstra.txt (8,03 KB)
TestScript.txt (1,26 KB)